INST326 Homework 5¶
20170711, IMDb and Classes¶
Below is Homework 5, which focuses on class design for representing objects in the IMDb dataset you used in Homework 4.
You will be graded on the following rubric:
- Class Design: You will be asked to design classes around the IMDb dataset. Your choice of classes should make sense given what we've learned in class and in the Py3OOP book and should have both attributes and behaviors.
- Documentation: Your code should be sufficiently documented so as to demonstrate you have an understanding of what your code is doing. This point is especially important if you are citing code from the Internet.
- Execution: Your code should at least execute. If your code does not run, you will get no points for this criteria.
- Correctness: Your code should implement the specifications provided correctly.
- Efficiency: While not a major factor, be prepared to have points counted off if your code is extremely inefficient (e.g., looping through a list without apparent need).
NOTE While you may work in groups to discuss strategies for solving these problems, you are expected to do your own work. Excessive similarity among answers may result in punitive action.

You are provided a file, movie_metadata.csv, that contains data from the Internet Movie Database (IMDb) for around 5,000 movies. This file came from Kaggle's datasets. Use this file to answer the following questions.
Part 1. Object-Oriented Design¶
Review the header for the movie dataset, and use this data to design a set of classes to model this data.
Identifying Objects¶
Develop a UML class diagram for at least four classes of objects in the IMDb dataset. Your classes should encapsulate all data contained in the given dataset.
You must include the following two classes:
- A Movie class
- An Actor class
NOTE : You can review UML class diagrams here: https://www.ibm.com/developerworks/rational/library/content/RationalEdge/sep04/bell/index.html
Attributes¶
For each class of object, include at least four attributes/behaviors (e.g., a Movie class has a title, budget, list of actors, and a content rating).
Class Interactions¶
For your class diagram, include the relationships among your four classes. Be sure to mark these relationships appropriately as inheritance relationships (outlined triangle arrows), associations (lines with no arrows or -> arrows), composition (solid diamond), or aggregation (outlined diamond).
What to Turn In¶
You should turn in the class diagram as an image file. You can draw the diagram and take a photo of it, scan the drawing, or use an existing graphic tool like Powerpoint, Word, Keynote, Omnigraffle, or other to construct this diagram.
Save your file as a valid PNG or JPG file named class_diagram.png and include the file in your homework submission.
NOTE: Your class diagram file should be in the same directory as this notebook. If so, you should see a copy of your class diagram below:
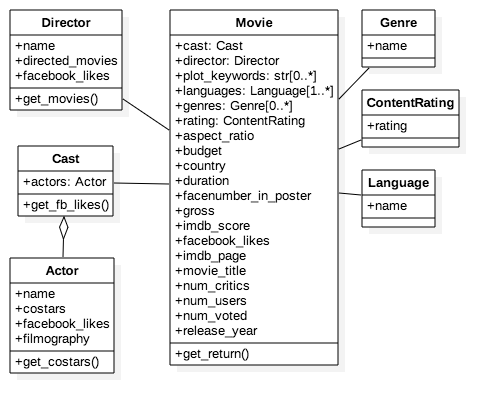
Part 2. Implementing Your Classes¶
In the space below, implement the classes you defined above. Include the following aspects:
Initializer¶
For each class of object, create an initializer that sets attributes to reasonable default values and requires initializer arguments for attributes that do not have default values (e.g., actor names or movie titles).
Requirements for Movie Class¶
Your Movie class should include a method/function
get_actors()that returns a list of Actor objects containing the actors who starred in the film.Your Movie class should include a method
percent_return()that calculates the ratio of gross box office income to the movie's budget.Your Movie class should include a method
parse_genre_string()that accepts an argument representing a genre string from the CSV file, parses this genre string into a list of genres, and returns a list of genres contained in this genre string.Your Movie class should include a method
__str__()that returns a string containing the movie title, rating, and release year.
Requirements for Actor Class¶
Your Actor class should include an attribute that contains a list of all Movie objects in which the actor has starred.
Your Actor class should include a method
get_filmography()that returns a list of all Movie objects in which this actor starred.Your Actor class should include a method
get_total_gross()that calculates the sum of all movie gross returns in which that actor has starred.Your Actor class should include a method
get_mean_gross()that calculates the average of all movie gross returns in which that actor has starred.Your Actor class should include a method
get_costars()that returns a list of Actor objects containing actors who have starred in movies with this actor.Your Actor class should include a method
__str__()that returns a string containing the actor's name.
# Implement here
class Director:
def __init__(self, name):
self.name = name
self.directed_movies = set()
self.facebook_likes = 0
def get_movies(self):
return self.directed_movies
class Actor:
def __init__(self, name):
self.name = name
self.costars = {}
self.filmography = set()
self.facebook_likes = 0
def get_costars(self):
return self.costars
def __str__(self):
return self.name
def get_filmography(self):
return self.filmography
def get_total_gross(self):
total_gross = 0
for movie in self.filmography:
if ( movie.gross != None ):
total_gross += movie.gross
return total_gross
def get_mean_gross(self):
total = self.get_total_gross()
return total / len(self.filmography)
class Cast:
def __init__(self, actors=[]):
self.actors = set(actors)
def get_facebook_likes(self):
likes = 0
for actor in self.actors:
likes += actor.facebook_likes
return likes
class ContentRating:
def __init__(self, rating):
self.rating = rating
def __str__(self):
return self.rating
class Genre:
def __init__(self, genre):
self.genre = genre
def __str__(self):
return self.genre
class Language:
def __init__(self, lang):
self.language = lang
class Movie:
def __init__(self, title, rating, year):
# Set from initializer
self.movie_title = title
self.rating = rating
self.release_year = year
# Create for setting later
self.cast = None
self.director = None
self.plot_keywords = []
self.languages = []
self.genres = []
self.aspect_ratio = None
self.budget = None
self.country = None
self.duration = None
self.facenumber_in_poster = None
self.gross = None
self.imdb_score = None
self.facebook_likes = None
self.imdb_page = None
self.num_critics = None
self.num_users = None
self.num_voted = None
self.color = None
def percent_return(self):
movie_return = None
if ( self.gross != None and self.budget != None):
movie_return = self.gross / self.budget
return movie_return
def get_actors(self):
return self.cast
def parse_genre_string(self, genre_str):
genres = []
for g in genre_str.split("|"):
genre = Genre(g)
genres.append(genre)
return genres
def parse_plot_string(self, plot_str):
plots = []
for g in plot_str.split("|"):
plots.append(g)
return plots
def __str__(self):
return "%s, %s, %s" % (self.movie_title, self.rating, self.release_year)
Part 3. Read a List of Movies¶
Write code below that reads the movie metadata file and populates lists of Movie and Actor objects.
# Implement here
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
# Read data into data frame, dropping rows with not-a-number values
df = pd.read_csv("movie_metadata.csv", header=0).dropna(axis=0)
# Maps for storing actors, directors, and movies by name
director_map = {}
actor_map = {}
movie_list = []
for row in df.itertuples(False):
# Create rating
rating = ContentRating(row.content_rating)
# Create language
language = Language(row.language)
# Create the movie
this_movie = Movie(row.movie_title, row.title_year, rating)
this_movie.languages.append(language)
this_movie.aspect_ratio = row.aspect_ratio
this_movie.budget = row.budget
this_movie.country = row.country
this_movie.duration = row.duration
this_movie.facenumber_in_poster = row.facenumber_in_poster
this_movie.facebook_likes = row.movie_facebook_likes
this_movie.gross = row.gross
this_movie.imdb_score = row.imdb_score
this_movie.imdb_page = row.movie_imdb_link
this_movie.num_critics = row.num_critic_for_reviews
this_movie.num_users = row.num_user_for_reviews
this_movie.num_voted = row.num_voted_users
this_movie.color = row.color
# Parse plot keywords
this_movie.plot_keywords = this_movie.parse_plot_string(row.plot_keywords)
# Parse genres
this_movie.genres = this_movie.parse_genre_string(row.genres)
# Get director or create if necessary
director = None
if ( row.director_name not in director_map ):
director = Director(row.director_name)
else:
director = director_map[row.director_name]
director.facebook_likes = row.director_facebook_likes
director.directed_movies.add(this_movie)
this_movie.director = director
# Pull actor from map or create if new
actor1 = None
if ( row.actor_1_name not in actor_map ):
actor1 = Actor(row.actor_1_name)
else:
actor1 = actor_map[row.actor_1_name]
actor1.facebook_likes = row.actor_1_facebook_likes
actor1.filmography.add(this_movie)
# Pull actor from map or create if new
actor2 = None
if ( row.actor_2_name not in actor_map ):
actor2 = Actor(row.actor_2_name)
else:
actor2 = actor_map[row.actor_2_name]
actor2.facebook_likes = row.actor_2_facebook_likes
actor2.filmography.add(this_movie)
# Pull actor from map or create if new
actor3 = None
if ( row.actor_3_name not in actor_map ):
actor3 = Actor(row.actor_3_name)
else:
actor3 = actor_map[row.actor_3_name]
actor3.facebook_likes = row.actor_3_facebook_likes
actor3.filmography.add(this_movie)
# Add costars
actor_list = [actor1, actor2, actor3]
for i in range(3):
if ( actor_list[i].name not in actor_map ):
actor_map[actor_list[i].name] = actor_list[i]
for j in range(3):
if ( i == j ):
continue
if ( actor_list[j].name not in actor_list[i].costars ):
actor_list[i].costars[actor_list[j].name] = actor_list[j]
# Create cast
cast = Cast(actor_list)
this_movie.cast = cast
movie_list.append(this_movie)
Part 4. Use Your Code¶
Use your code to answer the following two questions:
Find the movie with the highest ratio of gross to budget, and print its title, genres, starring actors, director, and release year.
Find the actor with highest average movie gross, and print his/her name, filmography, and costars. Use the
__str__()methods of Actor and Movie classes to print this data.
# Implement here
max_return = 0
max_movie = None
for movie in movie_list:
if ( movie.percent_return() > max_return ):
max_movie = movie
max_return = movie.percent_return()
print("Movie with highest return:", max_movie.__str__(), max_movie.percent_return())
print("Directed By:", max_movie.director.name)
print("Genres:", ", ".join([g.genre for g in max_movie.genres]))
print("Starring:")
for actor in max_movie.cast.actors:
print("\t",actor)
max_mean_gross = 0
max_actor = None
for actor in actor_map.values():
if ( actor.get_mean_gross() > max_mean_gross ):
max_mean_gross = actor.get_mean_gross()
max_actor = actor
print("Actor with highest average gross:", max_actor, max_actor.get_mean_gross())
print("Filmography:")
for film in max_actor.filmography:
print("\t", film)
print("Costars:")
for actor in max_actor.costars:
print("\t", actor)
max_total_gross = 0
max_actor = None
for actor in actor_map.values():
if ( actor.get_total_gross() > max_total_gross ):
max_total_gross = actor.get_total_gross()
max_actor = actor
print("Actor with highest total gross:", max_actor, max_actor.get_total_gross())
print("Filmography:")
for film in max_actor.filmography:
print("\t", film)
print("Costars:")
for actor in max_actor.costars:
print("\t", actor)
actor_map
with open("adj.csv", "w") as out_file:
for _,actor in actor_map.items():
adj = [(actor.name, x.name) for x in actor.costars.values()]
for tup in adj:
out_file.write("%s,%s\n" % tup)